Big Data Solutions using Apache Hadoop with Spark, Hive and Sqoop (3 of 3)
In the previous section, I shared steps to create a high availability production ready Apache Hadoop cluster with HDFS and Yarn. Follow Big Data Solutions using Apache Hadoop with Spark, Hive and Sqoop (2 of 3) for steps to configure Apache Hadoop cluster.
In this section, we will continue our cluster setup with Spark, Hive and Sqoop integration. Spark, Hive and Sqoop are some of the standard add-ons to Apache Hadoop that are needed and can handle 90% of daily workloads.
Spark is used for processing and transforming data, Hive facilitates data stored in HDFS in traditional SQL like data structure and Sqoop is used to import and export data between SQL and Hadoop File System.
SPARK Integration
Apache Spark is a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming. We use and focus more on Spark Streaming
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams. Data can be ingested from many sources like Kafka, Flume, Kinesis, or TCP sockets, and can be processed using complex algorithms expressed with high-level functions like map, reduce, join and window. Finally, processed data can be pushed out to filesystems, databases, and live dashboards. In fact, you can apply Spark’s machine learning and graph processing algorithms on data streams.

We will integrate Apache Spark 2.3.3 over Hadoop Cluster with Yarn as Master for all our processing. Therefore, it will not run as standalone process but as functionality/processing engine called in by running command spark-submit with master as Yarn. All the clustering and distributed processing will be taken care by Yarn.
Steps
→ Create a user spark with UID and GID as 1001 and home as /app/spark. This will be used to limit users to call spark commands from hadoop and spark user only.
→ Download the Tar Ball from (Spark Tar Ball)
→ Extract the Tar Ball under /app/hadoop and rename spark-2.3.3 to spark for simplicity.
→ Change user and group for all folders and files under /app/hadoop/spark including spark to hadoop.
→ The main configuration files are under /app/hadoop/spark/conf directory. The file system will look like.
.
├── bin #### This is where all binaries are present.
├── conf #### This is where all spark conf. are present.
├── data
├── examples
├── jars
├── kubernetes
├── LICENSE
├── licenses
├── logs #### This is where spark as process logs are saved but we are not concerned about it as we do not run in standalone.
├── NOTICE
├── python
├── R
├── README.md
├── RELEASE
├── sbin #### This is where all scripts are present but we do not use them as we do not run any process.
└── yarn→ Update .bash_profile with below lines in all the servers for hadoop user and create a replicate of .bash_profile under /app/spark so that spark user can also make use of it.
##SPARK ENV####
export SPARK_HOME=/app/hadoop/spark
export PATH=$PATH:$SPARK_HOME/bin→ The spark is integrated with cluster and we can use spark-submit or spark-shell to run jobs/commands. We can do that using hadoop and spark user.
→ Repeat the above steps to configure spark in Masternode2 for HA Setup.
Hive Integration
The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. Structure can be projected onto data already in storage. A command line tool and JDBC driver are provided to connect users to Hive.

Hive is to facilitate data stored in HDFS in more traditional SQL like data structure of databases and tables. We can create that using new data or data already present in HDFS. We do that by creating skeleton on top of the actual data sitting in HDFS. Also, Hive do not have a metastore of it’s own. It uses third party database to store and maintain one. In our example, we are going to use MySQL database for that.
Prerequisites
→ Download and configure MySQL server for hive metastore. It is recommended to have MySQL cluster of 3 or more nodes for redundancy. In our Example, we have only configured on Masternode1. Use How To Install MySQL on CentOS 7 | DigitalOcean or similar to configure.
→ We are using MySQL version 8.0.23. Download and save mysql-connector-java-8.0.23.jar. I will be used later.
→ Create a user hive with UID and GID as 1002 and home as /app/hive. This will be used to limit users to call hive command from hadoop and hive user only.
→ Update the core-site.xml file under etc/hadoop with hive settings and restart the Hadoop Cluster. The final file should look like
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. --><configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://testcluster</value>
</property>
<property>
<name>hadoop.proxyuser.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.server.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.server.groups</name>
<value>*</value>
</property>
</configuration>
Steps
→ Download the Tar Ball for Hive (Hive Tar Ball)
→ Extract the contents under /app/hadoop and rename apache-hive-3.1.2-bin to hive.
→ Change user and group for all folders and files under /app/hadoop/hive including hive to hadoop.
→ Add mysql-connector-java-8.0.23.jar under /app/hadoop/hive/lib/ location.
→ Login to the mysql shell as root and run the below commands to create a user and a metastore db.
mysql> CREATE USER 'hive'@'%' IDENTIFIED BY 'PASSWORD';
mysql> CREATE DATABASE metastore;
mysql> USE metastore;
mysql> SOURCE /app/hadoop/hive/scripts/metastore/upgrade/mysql/hive-schema-3.1.0.mysql.sql
mysql> GRANT all on *.* to 'hive'@'%';
mysql> flush privileges;Exit
→ The main configuration files are under /app/hadoop/hive/conf directory. The file system will look like.
.
├── bin ## Contains Binaries for execution.
│ ├── hive
│ ├── hive-config.sh
│ ├── hiveserver2
│ ├── hplsql
│ ├── init-hive-dfs.sh
│ ├── metatool
│ └── schematool
├── binary-package-licenses
├── conf ## Contains Configuration Files.
├── examples
├── hcatalog
│ │
│ └── share
│ ├── doc
├── lib ## Contains All Library Files.
|
└── scripts
|
|
└── metastore ## Contains SQL queries to create metastore DB.
└── upgrade
├── derby
├── hive
├── mssql
├── mysql
├── oracle
└── postgres→ Create hive-env.sh file under /app/hadoop/hive/conf with below contents
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.# Set Hive and Hadoop environment variables here. These variables can be used
# to control the execution of Hive. It should be used by admins to configure
# the Hive installation (so that users do not have to set environment variables
# or set command line parameters to get correct behavior).
#
# The hive service being invoked (CLI etc.) is available via the environment
# variable SERVICE# Hive Client memory usage can be an issue if a large number of clients
# are running at the same time. The flags below have been useful in
# reducing memory usage:
#
# if [ "$SERVICE" = "cli" ]; then
# if [ -z "$DEBUG" ]; then
# export HADOOP_OPTS="$HADOOP_OPTS -XX:NewRatio=12 -Xms10m -XX:MaxHeapFreeRatio=40 -XX:MinHeapFreeRatio=15 -XX:+UseParNewGC -XX:-UseGCOverheadLimit"
# else
# export HADOOP_OPTS="$HADOOP_OPTS -XX:NewRatio=12 -Xms10m -XX:MaxHeapFreeRatio=40 -XX:MinHeapFreeRatio=15 -XX:-UseGCOverheadLimit"
# fi
# fi# The heap size of the jvm stared by hive shell script can be controlled via:
#
# export HADOOP_HEAPSIZE=1024
#
# Larger heap size may be required when running queries over large number of files or partitions.
# By default hive shell scripts use a heap size of 256 (MB). Larger heap size would also be
# appropriate for hive server.# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/app/hadoop# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/app/hadoop/hive/conf# Folder containing extra libraries required for hive compilation/execution can be controlled by:
# export HIVE_AUX_JARS_PATH=
→ Create hive-site.xml file under under /app/hadoop/hive/conf with contents
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://172.26.0.0/metastore?createDatabaseIfNotExist=true</value> <!- Here IP is for mysql server and metastore is the db we are using for hive. ->
<description>JDBC connect string for a JDBC metastore </description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>PASSWORD</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>→ Create the folder structure in HDFS to store hive data.
hdfs dfs -mkdir /user/hive/warehouse
hdfs dfs -chmod -R a+rwx /user/hive/warehouse
hdfs dfs -chmod g+w /tmp→ Update .bash_profile with below lines in all the servers for user hadoop and create a replicate of .bash_profile under /app/hive so that hive user can also make use of it.
##HIVE ENV###
export HIVE_HOME=/app/hadoop/hive
export HIVE_CONF_DIR=/app/hadoop/hive/conf
export CLASSPATH=$CLASSPATH:/app/hadoop/lib/*
export CLASSPATH=$CLASSPATH:/app/hadoop/hive/lib/*
export PATH=$PATH:$HIVE_HOME/bin→ Change directory to /app/hadoop/hive/ and run the below command. It is needed to initiate the schema for hive. [Still trying to understand why to be in that directory]
$./bin/schematool -initSchema -dbType mysql
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/app/hadoop/hive/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/app/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:mysql://172.26.0.0/metastore?createDatabaseIfNotExist=true
Metastore Connection Driver : com.mysql.cj.jdbc.Driver
Metastore connection User: hive
Starting metastore schema initialization to 3.1.0
Initialization script hive-schema-3.1.0.mysql.sqlNOTE: — guava-*-jre.jar version under hadoop libraries and hive libraries can be different. They need to be of same version otherwise, you will get below error.
NOTE: - You can get exception "Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V"→ Once the above command successfully completes. You can run the hive command to login to the shell and play around.
$ hive
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/app/hadoop/hive/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/app/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Hive Session ID = 0413f7c7-26d4-4ca0-9c5b-4691816b37fdLogging initialized using configuration in jar:file:/app/hadoop/hive/lib/hive-common-3.1.2.jar!/hive-log4j2.properties Async: true
Hive Session ID = 9d297fa5-b2e3-4e0a-9290-84ba8ce71447
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive>
NOTE: — To install hive in another server of the same cluster, you can follow the same above steps except for ./bin/schematool -initSchema -dbType mysql as schema is already initiated and configured. If we try to do it again, we will get errors like Error: Table ‘CTLGS’ already exists (state=42S01,code=1050).
Sqoop Integration
Sqoop (SQL-to-Hadoop) is one of the most popular Big Data tools that leverages the competency to move data from a non-Hadoop data store by transforming information into a form that can be easily accessed and used by Hadoop. This process is most commonly known as ETL, for Extract, Transform, and Load. Sqoop is a tool designed to transfer data between Hadoop and relational database servers. It is used to import data from relational databases such as MySQL, Oracle to Hadoop HDFS, and export from Hadoop file system to relational databases.
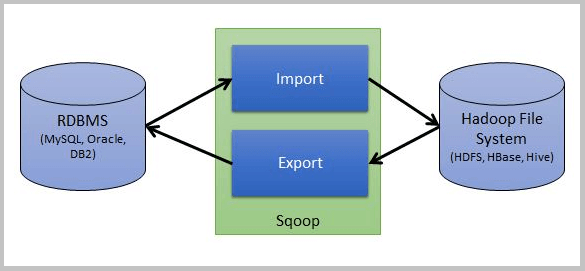
Steps
→ Create a user sqoop with UID and GID as 1003 and home as /app/sqoop. This will be used to limit users to call sqoop command from hadoop and sqoop user only.
→ Download the (Tar Ball Package) from the web.
→ Extract the contents under /app/hadoop/ and rename sqoop-1.4.7.bin__hadoop-2.6.0 to sqoop.
→ The main configuration files are under /app/hadoop/sqoop/conf directory. The file system will look like.
.
├── accumulo
├── bin ## All the Binaries are saved here.
│ ├── configure-sqoop
│ ├── configure-sqoop.cmd
│ ├── sqoop
│ ├── sqoop.cmd
│ ├── sqoop-codegen
│ ├── sqoop-create-hive-table
│ ├── sqoop-eval
│ ├── sqoop-export
│ ├── sqoop-help
│ ├── sqoop-import
│ ├── sqoop-import-all-tables
│ ├── sqoop-import-mainframe
│ ├── sqoop-job
│ ├── sqoop-list-databases
│ ├── sqoop-list-tables
│ ├── sqoop-merge
│ ├── sqoop-metastore
│ ├── sqoop-version
│ ├── start-metastore.sh
│ └── stop-metastore.sh
├── conf ## All the Conf. are saved here.
│ ├── oraoop-site-template.xml
│ ├── sqoop-env.sh
│ ├── sqoop-env-template.cmd
│ ├── sqoop-env-template.sh
│ ├── sqoop-site-template.xml
│ └── sqoop-site.xml
├── docs
├── hbase
├── hcatalog
├── lib ## All the libraries are saved here.
├── sqoop-1.4.7.jar
├── sqoop-patch-review.py
├── sqoop-test-1.4.7.jar
├── src
│ ├── docs
│ │ ├── dev
│ ├── java
│ │ ├── com
│ │ └── org
│ │ └── apache
│ │ └── sqoop
│ │ ├── accumulo
│ └── test
├── testdata
└── zookeeper→ Go to /app/hadoop/sqoop/conf and create sqoop-env.sh from sqoop-env-template.sh (No need to update anything, default is fine)
→ Copy the mysql-connector-java-8.0.23.jar used in hive integration under /app/hadoop/sqoop/lib/.
NOTE: — We will have to add more library jars for further integration. Example add ojdbc8.jar to integrate with Oracle.
→ Update .bash_profile with below lines in all the servers for user hadoop and create a replicate of .bash_profile under /app/sqoop so that sqoop user can also make use of it.
###SQOOP ENV###
export SQOOP_HOME=/app/hadoop/sqoop
export PATH=$PATH:$SQOOP_HOME/bin
export HCAT_HOME=/app/hadoop/sqoop/hcatalog
export HBASE_HOME=/app/hadoop/sqoop/hbase
export ACCUMULO_HOME=/app/hadoop/sqoop/accumulo
export ZOOKEEPER_HOME=/app/hadoop/sqoop/zookeeper→ Create these folder/directories if they do not exist already. They are needed to run import/export commands in the future. If we do not have these defined, our commands may fail or we may see warnings that they are not defined.
→ Everything is done, run the command $sqoop-version
2021-06-07 19:18:48,410 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
Sqoop 1.4.7
git commit id 2328971411f57f0cb683dfb79d19d4d19d185dd8
Compiled by maugli on Thu Dec 21 15:59:58 STD 2017→ Sqoop is integrated with Hadoop. Now we can run sqoop export import commands to move the data.
NOTE: — Based on source or sink you will use to import/export data, you will need to add dependent libraries under the SQOOP_HOME directory.
This marks the complete of section 3. We integrated Spark, Hive and Sqoop with our Apache Hadoop Cluster to run 90% plus of our workloads.
Overall we discussed about Hadoop Architecture with daemon and process details, configured an Apache Hadoop Cluster with HA setup and integrated Spark, Hive and Sqoop with it.
